使用colossalai分布式框架加速你的深度学习训练速度(一)安装与基本构建流程
前言(废话)
我们都知道,存在若干种方法可以加速我们在训练深度学习模型时的速度,本人大致知道如下几种(具体):
- mlkdnn加速
- cuda加速
- JIT加速
- 分布式训练
这些都是成效显著的加速方法,而且属于不同层面的加速。其中基于硬件GPU加速的是目前最主流、效果最好的方案了,在本人自己写框架的时候也发现,深度学习训练过程中也发现,其实可以优化的地方很多:batch size之间可以做并行,单个batch中基于不同的算子实现逻辑,也能做并行;每个训练集的batch之间也能做并行,如何做到高效调度本机GPU的计算资源,或是计算机集群的计算资源,使得整体的并行训练效率尽可能高?
HPC-AI Technology Inc. 和NUS的研究人员共同开发了“夸父”Colossal-AI,该框架提供了一个并行训练框架来尽可能提升(压榨)你的计算资源的使用效率。并自动实现了一些常用的训练技巧。
由于本人的笔记本前几天又在我relink的时候烂尾了,暂时无法参与本篇文章,所以这篇文章只能展示一下单机单卡的性能压榨,等我把笔记本修好了,再来尝试一下多机多卡分布式训练。
安装、验证
实验环境
| 平台\软件包 | 版本 |
|---|---|
| Win11 WSL2 | 0.58.3.0 |
| NVCC | 11.3 |
| Python | 3.6.9 |
| torch | 1.10.2+cu113 |
GPU为12G的RTX3060
请注意:
- 目前colossalai只支持Linux平台下的安装
- 尽量让你的NVCC版本>=11.3
不满足第一个条件,则下面pip install时大概率安装失败(今天上午提discussion时开发团队的成员秒回了会在Windows进行试验),不满足第二个条件,有可能失败。
本人主力机就是windows,可喜的是,目前的WSL2已经支持和宿主机共享显卡驱动了,因此,我在WSL2上完成了实验。
安装 colossalai
一句话就可以安装:
building wheel的过程很慢,因为会本地编译与CUDA相关的一些程序。
安装过程可能会出现报错,不过colossalai的setup.py写得很详细了,反正出错了就按照报错信息增加环境变量和安装包就行。
本人实测下来,你最好在colossalai安装前把tensorboard额外下载好,安装程序对tensorboard版本选取有bug。我在另一台电脑上安装时还遇到了交叉编译警告的问题,添加一个环境变量就好了:
$export TORCH_CUDA_ARCH_LIST="compute capability"
验证安装是否成功
我们使用官方给出的例子进行验证,首先创建环境变量DATA,等一下CIFAR-10数据集会下载在DATA代表的文件夹下。
(更多的例子请看官方的Example仓库 GitHub - hpcaitech/ColossalAI-Examples: Examples of training models with hybrid parallelism using ColossalAI)
复制下述代码到 eval.py
from pathlib import Path
from colossalai.logging import get_dist_logger
import colossalai
import torch
import os
from colossalai.core import global_context as gpc
from colossalai.utils import get_dataloader
from colossalai.context import Config
from colossalai.amp import AMP_TYPE
from torchvision import transforms
from colossalai.nn.lr_scheduler import CosineAnnealingLR
from torchvision.datasets import CIFAR10
from torchvision.models import resnet34
from tqdm import tqdm
global_config = Config({
"BATCH_SIZE" : 128,
"NUM_EPOCHS" : 2,
"CONFIG" : {
"fp16" : {
"mode" : AMP_TYPE.TORCH
}
}
})
def main():
colossalai.launch_from_torch(config=global_config)
logger = get_dist_logger()
# build resnet
model = resnet34(num_classes=10)
# build dataloaders
print("loading dataset...")
train_dataset = CIFAR10(
root=Path(os.environ['DATA']),
download=True,
transform=transforms.Compose(
[
transforms.RandomCrop(size=32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[
0.2023, 0.1994, 0.2010]),
]
)
)
print("finish loading dataset...")
test_dataset = CIFAR10(
root=Path(os.environ['DATA']),
train=False,
transform=transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[
0.2023, 0.1994, 0.2010]),
]
)
)
train_dataloader = get_dataloader(dataset=train_dataset,
shuffle=True,
batch_size=gpc.config.BATCH_SIZE,
num_workers=1,
pin_memory=True,
)
test_dataloader = get_dataloader(dataset=test_dataset,
add_sampler=False,
batch_size=gpc.config.BATCH_SIZE,
num_workers=1,
pin_memory=True,
)
# build criterion
criterion = torch.nn.CrossEntropyLoss()
# optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
# lr_scheduler
lr_scheduler = CosineAnnealingLR(optimizer, total_steps=gpc.config.NUM_EPOCHS)
engine, train_dataloader, test_dataloader, _ = colossalai.initialize(model,
optimizer,
criterion,
train_dataloader,
test_dataloader,
)
for epoch in range(gpc.config.NUM_EPOCHS):
engine.train()
if gpc.get_global_rank() == 0:
train_dl = tqdm(train_dataloader)
else:
train_dl = train_dataloader
for img, label in train_dl:
img = img.cuda()
label = label.cuda()
engine.zero_grad()
output = engine(img)
train_loss = engine.criterion(output, label)
engine.backward(train_loss)
engine.step()
lr_scheduler.step()
engine.eval()
correct = 0
total = 0
for img, label in test_dataloader:
img = img.cuda()
label = label.cuda()
with torch.no_grad():
output = engine(img)
test_loss = engine.criterion(output, label)
pred = torch.argmax(output, dim=-1)
correct += torch.sum(pred == label)
total += img.size(0)
logger.info(
f"Epoch {epoch} - train loss: {train_loss:.5}, test loss: {test_loss:.5}, acc: {correct / total:.5}, lr: {lr_scheduler.get_last_lr()[0]:.5g}", ranks=[0])
if __name__ == '__main__':
main()
然后打开命令行,运行:
$torchrun --nproc_per_node 1 --master_addr localhost --master_port 8008 eval.py
由于多机多卡涉及到的通信,所以需要开socket,不过本次是单机,这个参数设了也没啥用,只要确保master_port和本地开启的端口没有冲突就行。
运行效果:
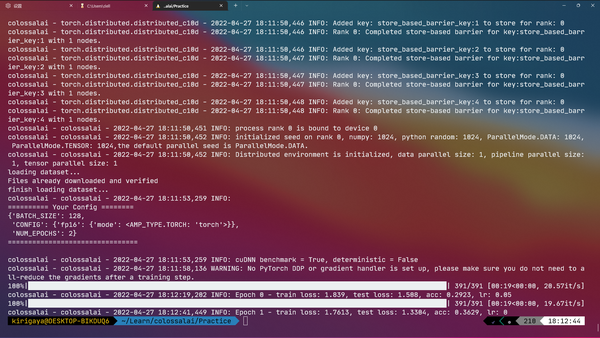
首次运行需要消耗时间下载CIFAR-10数据集
运行成功。
基本使用
在colossalai的官网上,给出了一套文字教程,个人认为讲得非常清楚:
使用colossalai框架进行训练的大致流程如下:
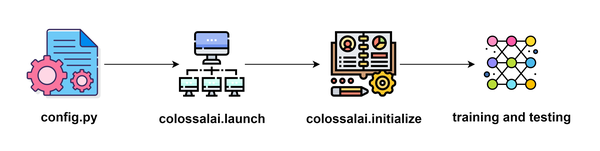
我会大致讲讲使用colossalai构建的每个步骤,这些步骤基本都可以和上述的例子对应起来。所以本人就不再写一个完整的例子了。
config.py 全局配置
colossalai通过一个python文件来作为全局的配置,假设我们把配置文件命名为config.py好了(你当然可以取别的名字),配置的内容可以在后续launch后通过 colossalai.core.global_context 进行访问。
比如我们的config.py是这样的:
那么在整个训练系统中,你可以这么访问它:
import colossalai
from colossalai.core import global_context as gpc
colossalai.launch(config='./config.py', ...)
# config.py已经被注册成了对象,直接通过属性值访问
gpc.config.BATCH_SIZE
除了基本的训练参数,比如批大小,训练轮数外,配置文件和整个训练系统需要使用的并行加速策略直接相关(说直接点,整个colossalai的并行策略就是在config.py中设置的),这部分配置的名字是固定的。
我把和并行策略相关的配置属性值列在下表中,附带对应的教程链接,方便查阅:
| 属性名称 | 含义 | 链接 |
|---|---|---|
| parallel | 并行配置,是一个字典,可配置的子项为数据并行、流水线并行和序列并行 | https://www.colossalai.org/zh-Hans/docs/basics/configure_parallelization |
| fp16 | 混合精度策略 | https://www.colossalai.org/zh-Hans/docs/features/mixed_precision_training |
| gradient_accumulation | 梯度累计次数 | https://www.colossalai.org/zh-Hans/docs/features/gradient_accumulation |
| clip_grad_norm | 梯度裁剪范数 | https://www.colossalai.org/zh-Hans/docs/features/gradient_clipping |
| gradient_handler | 自定义处理梯度同步的类 | https://www.colossalai.org/zh-Hans/docs/features/gradient_handler |
| MOE_MODEL_PARALLEL_SIZE | 一个进程中的混合专家模型数量 | https://www.colossalai.org/zh-Hans/docs/advanced_tutorials/integrate_mixture_of_experts_into_your_model |
一种可行的、较为简单的配置如下,很多任务中可以直接复制粘贴:
from colossalai.amp import AMP_TYPE
BATCH_SIZE = 128 # 批次大小
NUM_EPOCHS = 10 # 训练10轮
fp16 = dict(
mode=AMP_TYPE.TORCH # AMP后端是pytorh
)
parallel = dict( # 并行策略,请注意,pipline的取值和tensor的size的乘积为你GPU的数量(此例中为2 * 4 = 8)
pipeline=2,
tensor=dict(size=4, mode='2d')
)
colossalai.launch 启动
通过launch可以将配置文件注入系统中,并初始化各种与网络硬件相关的配置。
关于分布式训练有几个比较重要的几个概念:
- host: 主训练机的IP
- port: 主训练机的端口
- host: 训练网络中机器的ID
- world size: 网络中机器的数量。
将这些参数注入系统的方法有很多种,你可以在启动 Colossal-AI | Colossal-AI (colossalai.org) 找到。如果你使用的是版本大于1.10的pytorch,可以使用torch自带的脚本torchrun来启动并输入参数:
参数如下:
- --nproc_per_node : 每个节点GPU的数量
- --master_addr : 对应上述 host
- --master_port : 对应上述的port
倘若你的训练脚本为train.py,本地有三块GPU,只用一台机器训练,那么启动训练的脚本为:
$torchrun --nproc_per_node 3 --master_addr localhost --master_port 8001 train.py
上述命令会在该机器上的8001端口开启一个训练服务,如果8001被占用,也可以使用别的端口。
colossalai.initialize 初始化(模型封装)
在launch之后,我们就不需要关心系统如何调度计算资源了,我们只需要关心单台机器上如何跑训练代码。
除此之外,colossalai还做了一件很nice事情,就是将已有的训练代码进行二次封装,无论用户采用什么模型,什么优化器,什么学习率动态更新算法,什么数据加载器,通过colossalai封装后,后续代码都会变得几乎一模一样。
假设我们已经历经千辛万苦,搞到了训练的几大要素:
# 后端采用pytorch
colossalai.launch_from_torch(config="config.py")
# 1. 训练集加载器
train_dataloader = MyTrainDataloader()
# 2. 测试集加载器
test_dataloader = MyTrainDataloader()
# 3. 模型
model = MyModel()
# 4. 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 5. 损失函数
criterion = torch.nn.CrossEntropyLoss()
通过colossalai提供的初始化函数可以进行一步封装:
# 返回四个值: engine对象,训练集加载器,测试集加载器,学习率更新器(这不是必须的,从简,不提)
engine, train_dataloader, test_dataloader, _ = colossalai.initialize(
model,
optimizer,
criterion,
train_dataloader,
test_dataloader,
)
engine封装
其中的engine就是对模型、优化、损失函数的封装,它同时继承了模型,优化器和损失函数的一堆方法,常用操作我都整理在下表中了:
| 方法 | 解释 |
|---|---|
| engine(inputs) | 前向计算,等价于model(inputs) |
| engine.zero_grad() | 清空梯度,等价于optimizer.zero_grad() |
| engine.step() | 更新参数,等价于optimizer.step() |
| engine.criterion(output, label) | 计算损失,等价于criterion(output, label) |
| engine.backward(loss) | 反向传播,等价于loss.backward() |
| torch.save(engine.model.state_dict(), f=…) | 保存模型 |
| engine.model.load_state_dict(torch.load(f=…)) | 读取模型 |
| engine.train() | 训练模式,等价于model.train() |
| engine.eval() | 评估模式,等价于model.eval() |
请注意,使用engine封装后的模型的state_dict()的每一个key会多出一个”model.”的前缀,它无法直接装载进入一个没有封装成engine的model中,如果你偏要这么做,那么请在load之前对每个key使用lstrip(“model.”)方法进行前缀去除。
其余的步骤和torch常规训练一致。此处就不赘述了。需要注意的是,由于需要使用torchrun脚本进行启动,请不要直接在jupyter notebook中启动训练代码。
除了engine对象,官方还提供了一个更加高级的封装Trainer,它是对engine的进一步封装。使用Trainer,就能实现Keras风格的直接使用fit函数进行拟合,并且Trainer还提供了使用钩子函数的接口,由于本次实验未使用Trainer,所以留到下一章去讲了,感兴趣的读者可以参考colossalai的官方文档来学习Trainer:
如何在训练中使用 Engine 和 Trainer | Colossal-AI